How Did I Improve the Performance of my Website using Protobuf?
Anne-Sophie Jourlin8 min read
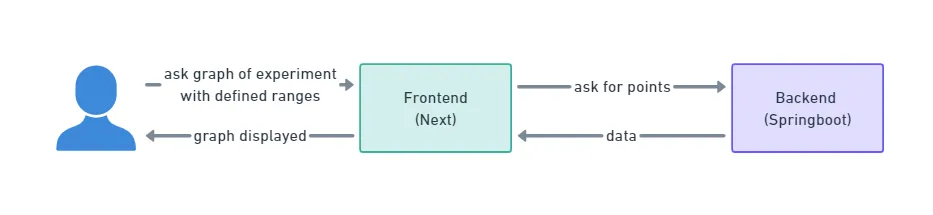
For my very first project at Theodo, I worked on a website designed for scientists who wanted to track the progress of an experiment. My task involved improving graphs with large amounts of data. However, the data retrieval process turned out to be a battlefield against lagging performance. Depending on the selected time ranges, users had to wait for more than 10 seconds to retrieve and display the data on the graph.
The process started with scientists selecting the parameters for display. Then, the Next frontend called the Springboot backend, which retrieved data from a third-party source. The data were then deserialized, serialized again, and sent back to the frontend.
One issue I observed was the inefficient serialization and deserialization of the large payloads. The payloads were read as strings in JSON format, requiring additional time for reading and casting them into the appropriate classes.
The challenges and a tool
I wanted to tackle this problem of the use and transmission of complex data, which is an IT challenge in many cases, and even more so when building a web app. The first difficulty is the performance of the application and the complexity of handling the data that is received, manipulated, and transmitted within it. The second issue is the language changes that can occur between the different services that will interact with the data. In the case of my web app, the backend and the frontend are in different languages. Since types cannot be shared directly, each change in the data format implies modifications in the two parts of the app.
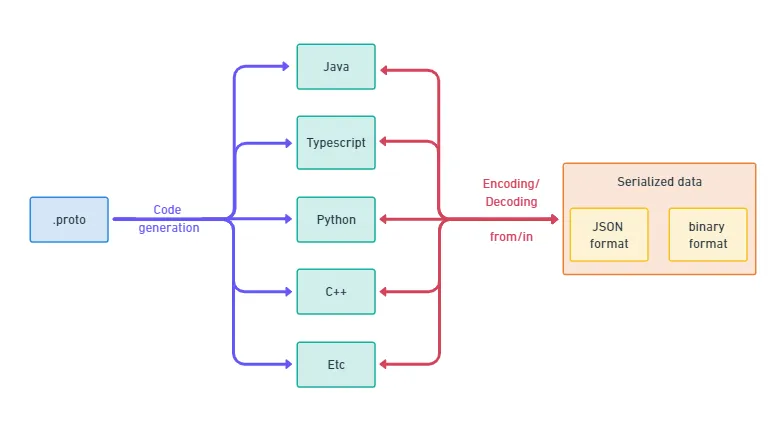
I once ran into a really interesting tool: Protobuf, which is short for Protocol Buffers. This tool was developed by Google and is described as XML but “smaller, faster, and simpler” (https://protobuf.dev/). Like XML, Protocol Buffers allow you to write and read structured data easily, but also to use it directly in several languages with optimized mechanisms for serializing the structured data.
In this article, I want to help you discover more about Protobuf through explanations and my personal experience so that in a few minutes you can see the added value of the tool and in which projects Protobuf shows its true power.
How did I use Protobuf?
Classes construction
The first step to using Protobuf on my website was to construct classes to contain the data I wanted to send.
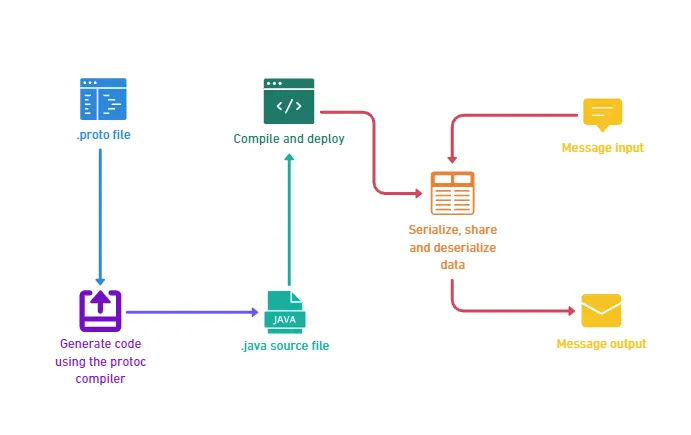
Protobuf is “Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data” according to the online documentation. Knowing this is a good start, but what does it concretely mean? It means that the process to use Protobuf is to write in a file the definition of the structure of your data, and then you simply use the compiler to generate your class in the right languages.
In my case, the scientists needed to display values such as the temperature through time. A logical structure can be a basic data point structure composed of the timestamp and metadata linked to the measure (name of the project, start date,…) with the data that needs to be displayed. To have this structure, I simply declared it in two .proto files:
- A first one for the basic structure:
syntax = "proto3";
package protos;
message BasicDataPoint {
string timestamp = 1;
string experimentName = 2;
}
- A second one specific to the temperature data points:
syntax = "proto3";
package protos;
import "basicDataPoint.proto";
message TemperatureDataPoint {
BasicDataPoint basicDataPoint = 1;
float temperature = 2;
}
The declaration of the structure is really simple and looks a lot like a JSON file.
Now you can generate the classes in the language of your choice using the protoc compiler. Some languages are not supported natively, for example, JavaScript and TypeScript: there are some great packages like protobuf-ts to generate the classes and use Protobuf in these languages. I needed Java and Typescript so I generated each class in both languages.
Needed functionalities
I had my classes, and I then needed to use them to carry my data.
After building my classes, I replaced my old Java builders with the one for the generated classes like this:
TemperatureDataPoint myTemperatureDataPoint = TemperatureDataPoint
.newBuilder()
.setTemperature(point.getTemperature())
.setBasicPoint(BasicDataPoint
.newBuilder()
.setTimestamp(point.getTimestamp())
.setExperimentName(point.getExperimentName())
.build())
.build();
Then you have several choices to format the data before sending it:
- Letting Java formatting it as a JSON
- Using the Protobuf method
toJsonto convert it as a JSON - Encode it using Protobuf’s methods to reduce the size of the message
I used this last method as I wanted my message to be as small as possible. The Java code to encode the message is the following:
String encodedMessage = Base64
.getEncoder()
.encodeToString(myTemperatureDataPoint.toByteArray());
Then I just needed to get the data back in my Javascript frontend, to decode it:
const binaryTemperaturePoint = Buffer.from(rawDataReceived, "base64");
const temperatureDataPoint = TemperatureDataPoint.fromBinary(binaryTemperaturePoint);
Impacts on the performance
Time for serialization and deserialization
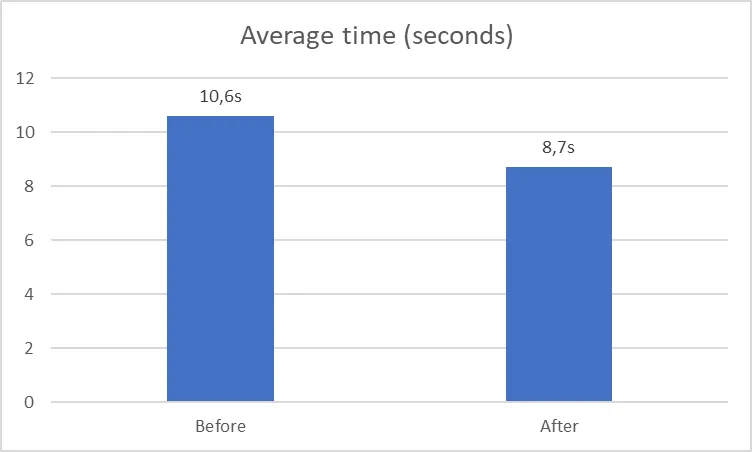
After integrating Protobuf, I conducted a performance test on my application to evaluate the impact on the endpoint’s efficiency. The results indicated a noticeable enhancement in performance: I measured an average time of 10.6 seconds against 8.7 seconds now. An improvement of more than 15%!
Data compression
Regarding the data compression, I had to explore solutions as there is no date format in Protobuf! It leaves us with two main options:
- Use strings, with different format
- Use integer on 64 bits to store unix timestamps in milliseconds
As I wanted to maximize the compression, I tested both. Following are my findings:
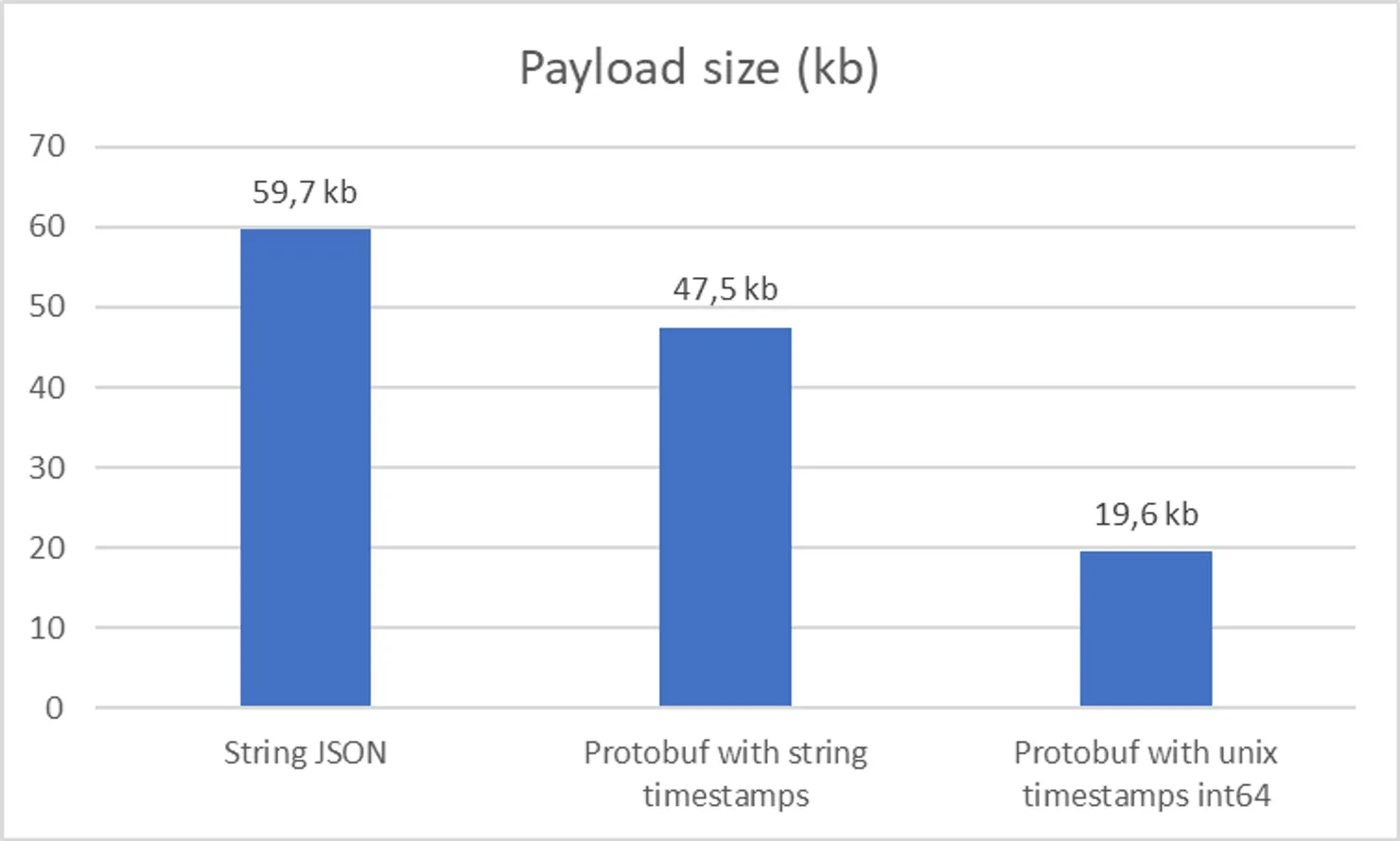
Integers are the best choice here with a surprising 70% reduction in payload size. This highlights why testing your assumptions is important!
Is Protobuf a good fit for your project?
If you have to deal with huge payloads in requests and big serialization and deserialization times, Protobuf is quite a good fit! On top of that you get shared interfaces between your applications independently of used languages.
Here are some more detailed criteria I use to choose if I should use Protobuf on a project:
Advantages
- Smaller payloads
- Faster serialization and deserialization
- Code generation from interfaces definition
- Less exhaustive types
Limitations
- Endpoints are harder to debug
- Cost of migration for existing applications
- Restrictions on the data structure
- Less comprehensives typing features available compared to typescript (inherited from golang)
The first two advantages were my motivation to select this tool.
The third one is an advantage in the method of conception: when using Protobuf, you have to first think about the interface before starting anything, which can be seen as a constraint but is, in fact, a good practice. Note that as each field encloses its index, it is easy to add one as it doesn’t impact the other fields, but you have to be cautious to do it on every service of the application.
The last advantage is also a limitation: in Protobuf you don’t have as many types supported as for example in Java. But from all the primitive ones, you can build all cases and are not limited. In my case, I had to work on the type for my timestamps, as I could use both numbers and strings but not directly a date type as I was used to in Java. I kept the strings as it meant less rework on my application but discovered that it greatly increased the size of my payload.
Regarding the limitations, the most important one is that the binary payloads are not readable for humans without extra tooling, so they become harder to debug compared to JSON. The second limitation which I had to deal with since I was integrating Protobuf in an existing application was the inability to use inheritance to define interfaces, meaning some rework to use only composition instead.
Going further
Protobuf is, of course, not the only option to solve the difficulties I first encountered. Against these issues, there are a whole bunch of solutions available, and some are explained in other articles of this very blog: you can use Nest for your backend, meaning sharing typescript interfaces or you can share types using OpenApi schema with Orval. But do give Protobuf a try! As it also allows you to improve your performance as well as making your application easier to scale.
I hope this article provides a better understanding of Protobuf and its strengths through my use case so that if your project can be improved by its use, you now understand to which point.