Whisper to your keyboard: Setting up a speech-to-text button
Jérémie Chauvel4 min read

Long story short: I broke my arm while riding my bike and I can’t type. Quite the problem as typing is a key part of my daily life as a software engineer. So I decided to add a speech to text button to my keyboard. Here’s how I did it.
How to transcript speech to text on linux
First, I looked into how to transcript speech to text on linux. I found a few solutions:
- Whisper.cpp: a way to run the OpenAI whisper model locally
- OpenAI’s API: the original Whisper model as a pay as you go API
- Deepgram: a pay as you go service that offers a speech to text API
After testing whisper.cpp on my machine, it was too slow and inaccurate (out of the box), so I decided to use an API and abandoned the idea of running it locally (for now).
So I registered for an OpenAI account and tried their API:
(you can download an example recording here)
FILEPATH="./recording" # path to the recording without extension
curl --request POST \
--url https://api.openai.com/v1/audio/transcriptions \
--header "Authorization: Bearer $OPEN_AI_TOKEN" \
--header 'Content-Type: multipart/form-data' \
--form file="@$FILEPATH.wav" \
--form model=whisper-1 \
--form response_format=text \
-o "${FILEPATH}.txt"
It’s quite magical, already I could transcript my voice to text.
How to record your microphone on linux
This one was a challenge for compatibility and device selection, but basically, what you want to do is record your microphone as a .wav file and save it. (I could not make mp3 encoding work reliably and it was not required)
First use arecord to list your available devices:
arecord -l
Then you should be able to test which input device is your microphone by recording a few samples:
FILEPATH="./recording"
AUDIO_INPUT="hw:0,0" # your microphone device, test with a few devices to find the right one
arecord --device="$AUDIO_INPUT" --format cd "$FILEPATH.wav" --duration=10
How to write the text file emulating a keyboard
This one is quite easy, I used xdotool to emulate a keyboard and write the text file:
FILEPATH="./recording"
perl -pi -e 'chomp if eof' "$FILEPATH.txt" # remove trailing newline if any to avoid sending an extra newline keypress
xdotool type --clearmodifiers --file "$FILEPATH.txt"
Putting it all together: a button to transcript speech to text
Now that we have all the pieces, we can put it all together in a script:
#!/usr/bin/env bash
# usage: exec ./voice-typing.sh twice to start and stop recording
# Dependencies: curl, jq, arecord, xdotool, killall
set -euo pipefail
IFS=$'\n\t'
# Configuration
readonly PID_FILE="${HOME}/.recordpid"
readonly FILE="${HOME}/.voice-type/recording"
readonly MAX_DURATION=15
readonly AUDIO_INPUT='hw:0,0' # Use `arecord -l` to list available devices
start_recording() {
mkdir -p "$(dirname "$FILE")"
echo "Starting new recording..."
nohup arecord --device="$AUDIO_INPUT" --format cd "$FILE.wav" --duration="$MAX_DURATION" &>/dev/null &
echo $! >"$PID_FILE"
}
stop_recording() {
echo "Stopping recording..."
if [ -s "$PID_FILE" ]; then
local pid
pid=$(<"$PID_FILE")
kill "$pid" && wait "$pid" 2>/dev/null || killall -w arecord
rm -f "$PID_FILE"
return 0
fi
echo "No recording process found."
}
write_transcript() {
perl -pi -e 'chomp if eof' "$FILE.txt"
xdotool type --clearmodifiers --file "$FILE.txt"
}
transcribe_with_openai() {
curl --silent --fail --request POST \
--url https://api.openai.com/v1/audio/transcriptions \
--header "Authorization: Bearer $OPEN_AI_TOKEN" \
--header 'Content-Type: multipart/form-data' \
--form file="@$FILE.wav" \
--form model=whisper-1 \
--form response_format=text \
-o "${FILE}.txt"
}
main() {
if [[ -f "$PID_FILE" ]]; then
stop_recording
transcribe_with_openai
write_transcript
else
start_recording
fi
}
main
The script needs to be run twice to start and stop recording. It will then transcript the recording and write the text to the current window.
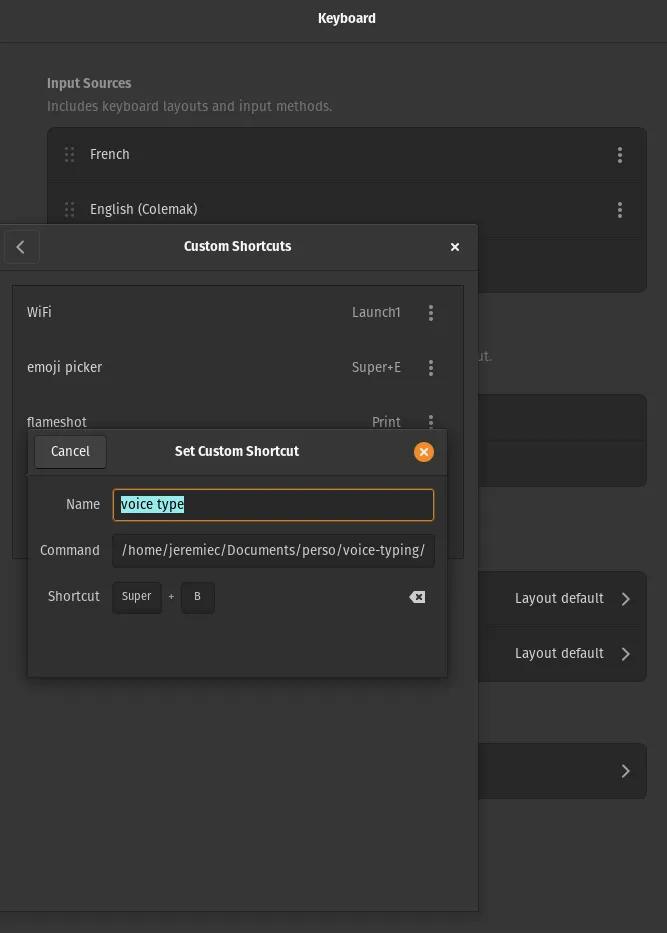
To trigger it with a button, simply add a keyboard shortcut to run the script in your keyboard configurations settings on your linux distribution.
Conclusion and next steps
It was a fun little project to do, and it’s quite useful to be able to type with your voice. I’m not sure I’ll keep using it after my arm heals, but it’s a nice option to have.
Since using whisper was a little slow, I tried and switched to Deepgram for faster (and sometimes more accurate) transcriptions. I published the complete script on github, you can find it here, it checks for requirements and handles errors a little more gracefully.