Manage your technical debt roadmap right from your code 🚀
Maxime Thoonsen14 min read
Exec summary:
- Technical debt leads to bugs creation: the number of bugs and the number of design flaws (technical debt) are 0.92 correlated in a study from the Software Engineering Institute
- Static analysis tools like SonarQube are massively used (100k+ users) to chase quality defects, but they can’t replace human intelligence
- Bug tracking system are time-consuming and don’t help developers while they code
- Our tool Tyrion fixes these problems and allows developers to see quality problems right in their IDE
Quality is worth its investment
Martin Fowler in his famous article on quality explains why investing in software quality is cheaper than not investing in it.
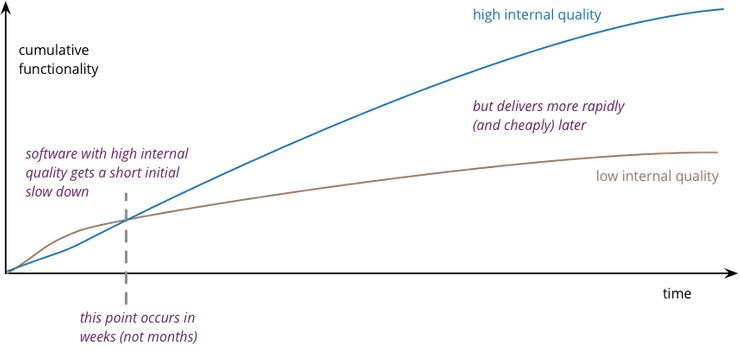 Why quality in software is cheaper than no quality
Why quality in software is cheaper than no quality
This knowledge has also long been known for lean practitioners: “If you focus on quality, you will deliver a high quality product on time. If you focus on delivery, you will deliver a low quality product late.”
Why is that? If you focus on delivering things right the first time you will have less rework to do and then save time in the long run. Teams that don’t do that end up spending most of their time fixing bugs.
 Low quality leads to too many bugs and missed deadlines
Low quality leads to too many bugs and missed deadlines
Static analysis tools are mandatory but not enough to monitor quality
Once you know you want to deliver quality on the long run, there are a lot of things to do: identifying best practices, tech trainings, problem solving, quality tooling, setting up all kind of monitoring, choosing quality KPIs …
If you are serious about keeping the quality of the codebase high, you need to proactively chase, monitor and resolve code quality defects. Even if you have set up all the best linters rules and have a highly trained team, in the long run you will have defects. Indeed, there are a lot of defects that linters can’t detect: non homogeneous code and architecture, wrong patterns usage, naming not coherent with business…
A widespread strategy is to monitor quality by static analysis tools like SonarQube or CodeClimate. These tools have some advantages:
- ✔️You get a quality score without extra work from a developer (once the tool has been set up which can be quick)
- ✔️Results are objective
- ✔️They give you a list of piece of code you need to change and which good practices have not been followed
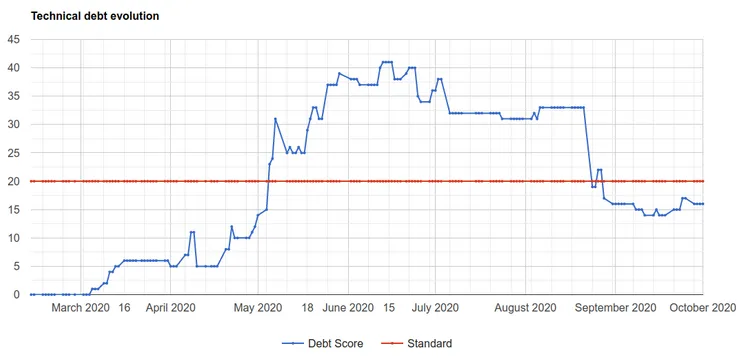
You can have graphs like this one which give you the trend of your technical debt and show you if the situation is getting better or worse.
 A SonarQube debt graph from a current project
A SonarQube debt graph from a current project
When talking with tech leads and CTOs, many of them told me that SonarQube has been efficient to help their team keep the quality of their code high.
Static Code Analysis Tools (SCAT) provide objective metrics and insights of the code quality and technical debt. However, these tools require a real integration effort. Such tools without a team adoption and training are of little value. On the opposite, used by trained developers, with a pragmatic understanding of the metrics and warnings, these tools offer a lot of clues on the next refactoring needed to reduce project entropy, on the security breaches still to address and on the potential bugs to review. SCAT warnings and suggestions must be used as starting points of developers' discussions around quality standards. SCAT must not be considered as referees stating good/bad quality points of a project or a team.
It has also been proven to be effective in some studies like Oswal, Nikhil. “Technical Debt: Identify, Measure and Monitor.” (2019)
However, those tools have also limitations:
- ❌ they create quite a lot of false positive (labeling a piece of code as bad when it is good) and false negative (missing some bad piece of code) requiring times to sort everything.
- ❌ they can’t inspect all aspects of a project. For example some defects like a wrong or non homogeneous directories’ organisation are never detected
Academic research while confirming the positive impact of static analysis tools insist that they are not mature enough to only rely on them. For example, to assess if a defect will create a bug, Valentina Lenarduzz warns us in her 2019 study “Are SonarQube Rules Inducing Bugs?”: “SonarQube violation severity is not related to the fault-proneness and there-fore, developers should carefully consider the severity as decision factor for refactoring a violation.”
This is exactly what Bill Clark explained very well in his article “A TAXONOMY OF TECH DEBT”, human can provide much more valuable information about a piece of code with technical debt like the contagious aspect: “Is it likely this bad code practice could spread somewhere else by copy/paste?”
Performant quality monitoring requires human analysis
As we just see, human analysis provides complementary information to static analysis tools:
- ✔️human can analyse every aspect of the project: architecture, naming, easiness of understanding, maturity of library and frameworks
- ✔️they can provide much more information about the problems they detect since they understand the context around the codebase
- ✔️they can provide a prioritization of the problems
The more the developers in your teams are trained about writing quality the more efficient they will be to detect defects. This is another reason why you should invest a lot in training if you want to achieve high quality in your code.
You also need to agree on the best way to write things: what is OK and what is not OK to write in the code. For example, these pieces of code are doing the exact same thing in Symfony.
/**
* @ORM\Column(unique=true)
*/
private $email;
/**
* @ORM\Column(type="string", length=255, unique=true)
*/
private $email;
Both ways have their advantages: the former is shorter to write/read and the latter is more explicit. I prefer the explicit version because I think in this case the tradeoff between the code being super clear and having more words to write and read is worth it. Some other people could say that it is not worth it to add the type and length because it’s the default.
Who is right is less important than having your team agreeing in the standard way of doing it. Because once you agreed, people are autonomous to write and check quality on their own regarding this standard making little by little the whole code base coherent.
The main drawback of human analysis is that they require a lot of effort to get and update the information about the overall quality.
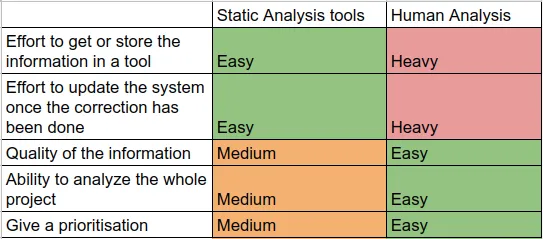 Comparison between static analysis and human analysis for software quality
Comparison between static analysis and human analysis for software quality
Existing tools are time-consuming and don’t help devs when they are coding
At Theodo we experienced several systems to track self admitted technical debt (SATD, as software quality researchers calls it).
-
On small or short projects, we use a special column in Trello/Jira/Monday/Google doc to track tasks we need to do to fix quality problems. This works OK as long as the team fixes everything quickly, so the column doesn’t get too long and messy.
-
When the project grows we quickly need a real tech roadmap on a separate board.
 Example of debt management using Trello
Example of debt management using Trello
We can also use a specialized bug tracking tool like Bugzilla or Bugherd. It works well, but it has two drawbacks:
- ❌ it is time-consuming to update it when an item has been fixed or is no longer valid
- ❌ developers don’t see the defect in their IDE while coding and thus could copy/paste it creating the contagious aspect of the debt explained by Bill Clark.
Introducing Tyrion: a tool to help teams track software quality through human analysis
I initiated Tyrion to remove those main drawbacks and be able to:
- ✔️Document the debt while coding directly in the IDE
- ✔️Painlessly update the debt tracking system when something has been fixed
- ✔️Quickly get an overview and the trend of the debt
Writing comments in the code to map the debt
Instead of registering all technical defects in a tool, the main idea of Tyrion is to add them directly in the code base as comments. Tyrion will parse these comments to generate the debt graphs or CSV files so you can analysis the debt.
The syntax of the comment is straightforward: the only thing you need to add to a classic comment is a type to allow Tyrion to group them:
// TODO DEBT_TYPE "Author: comment"
I like the following example from a current project. Albéric and Emyly are working on improving the accessibility of the webapp. Nothing urgent from the business and nothing requires immediate change from a technical point of view. But still, they know they can do this piece of code better, so they mark it as debt to improve it a bit later.
// TODO accessibility "Alberic: Add keyboard behaviours and focusability"
export const Select: React.FC<Props> = ({
Even if you don’t use Tyrion, adding debt comments in the code is valuable by it-self. It trains developers to evaluate the quality of the code while they are coding. It also partially protects you again the contagious effect of the debt because if you have correctly marked with comments the debt in the code, developers will think twice before copy/pasting a piece of code that is marked as a debt.
If you have a large code base, it can take a while to document the whole technical debt. You can do it gradually during few weeks. While working on some part of the app each member of your team will read different files and find something to mark as debt. By doing that you will create little by little the debt map of your project. Of course, it’s better to fix a problem when you see it but for various reason you don’t always have the time to do it.
If your project is of reasonable size, you can also organize a big debt mapping session one afternoon.
Using the CLI to generate the first graph
Once you have commented at least a part of the debt you have in your project, you can start using the Tyrion CLI.
First you need to download it with: npm i -g tyrionl or yarn global add tyrionl
Then just run tyrion in the root directory of your project.
It will scan your files to look for TODO, FIXME or @debt strings in the comments and then assume it is a debt comment.
This first mode is useful to get information of the current debt status of your project. It can help you respond to question such as “How much debt do we have right now?” or “What kind of debt do we have most?”
If I run Tyrion in the frontend part of our webapp, I got the following graph where we can find the acessibility type
of debt from the above debt comment among other types we use on the project.
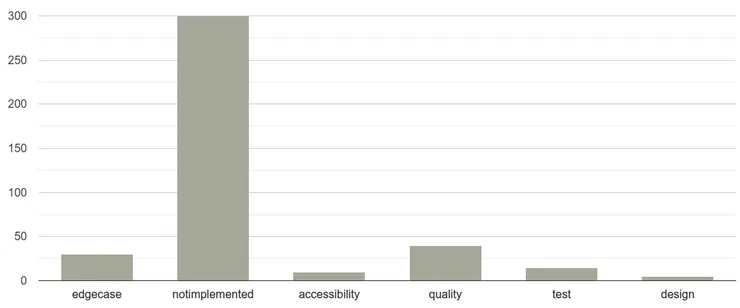 An example of the debt graph showing the current distribution of types of debt
An example of the debt graph showing the current distribution of types of debt
You can customize the weight of each type on the global debt score
All kind of debt doesn’t have the same impact. A security issue can be more critic than an over complex function.
So you may want to weight differently each kind of debt. This can be done by creating a .tyrion-config.json file
in the root of your project. You can then assign different value to each type of debt.
Here is the default configuration:
{
"pricer": {
"bug": 100,
"architecture": 100,
"bugRisk": 5,
"security": 100,
"securityRisk": 10,
"quality": 5,
"test": 5,
"doc": 3,
"ci": 30,
"deploy": 10,
"devEnv": 10,
"outdated": 5
},
"standard": 100,
"ignorePath": ["node_modules", "README.md"]
}
The trend of the debt may be the most important information
After a while of commenting debt in your code, you will be able to use the second mode that will analyse your Git
history and will create a graph of the evolution of your debt.
The command to get it is tyrion -e 200. You can replace 200 with the number of days you want to scan backward.
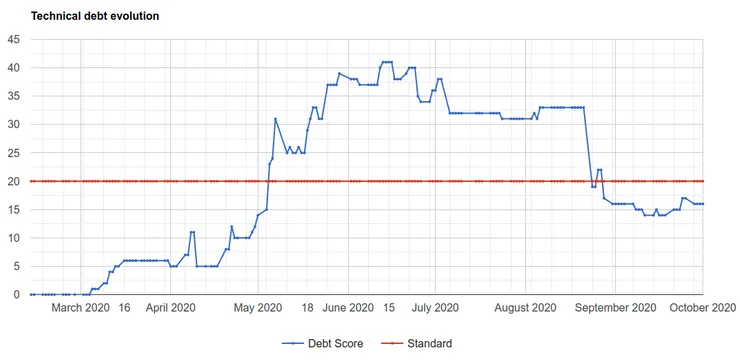 An example of a debt report showing the evolution of the debt
An example of a debt report showing the evolution of the debt
This kind of report will help you and your team respond to the question “Are we creating debt or increasing quality?” It is important to know because if the trend of your debt is increasing, you should invest more in quality. Remember you won’t go faster by overlooking quality 😉.
Sharing it with the product/business team
If you are reading this, you are probably a developer, and you probably want to spend more time on quality. You may not be able to do so because someone in the business side of your project prefer that you focus on a short term deadline.
So you need to negotiate with this person. This tool was also build to help you to do so by providing graph and data to support your case.
 Sharing quality data with product team is a good way to onboard them on the topic
Sharing quality data with product team is a good way to onboard them on the topic
Conclusion
Keeping a high level of code quality on a project for years is something very difficult. One positive side effect of using Tyrion on a project is that developers can grow their quality awareness while coding. If all developers of your team ask them-selves “Is this piece of code I’m writing/reading the best we can do?” for each feature, you will be on a good track to keep the quality high on the long run.
- 📧 by email
- 🐦 on twitter
- 🐙 by leaving an issue or a pull request on the Tyrion repository
- 💬 by leaving a comment below


