Do not Forget to Cover your Import Scripts with Tests!
Antoine Toubhans4 min read

A major issue during my last project was regressions in production occurring twice a week. The PO felt anxious, and the project was in danger,
even though the team was reactive and able to quickly fix regressions.
Why so many regressions?
A good explanation could be the lack of tests. However, both Node.js/Express.js back-end and AngularJS front-end were 80% covered by unit/end-to-end tests. Tests are supposed to prevent regressions so what’s wrong with them?
Something was clear: most regressions were related to the data.
Data regression: a case study
In our app, people can have phone numbers on their profile page. The app receives on a daily basis a file containing people IDs and phone numbers. The team wrote a script loading phone numbers into the database every night.
A regression occurred on the second day: people have the same phone number twice on their profile pages :( This is typically a data issue:
- the front-end showed twice the same phone number on profile pages because that’s what it received from the back-end;
- the back-end served twice the same phone number because people have twice phone numbers in the database.
The culprit was the import script that did not remove old phone numbers before loading the new ones. Neither back-end tests nor front-end tests could have spotted this issue. If we look at the data flow of the application: import scripts lack tests!
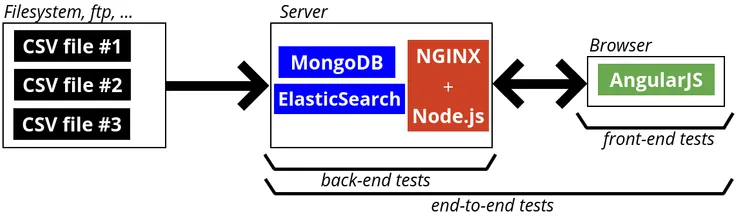
What do we need to test?
Data come from CSV files we received daily through a FTP. A Python script fetches the files and loads data in the database every night.
File encoding
Files are encoded in various formats: UTF-8, ISO-8859-1, Windows-1252 and even EBCDIC!. Checking that scripts can properly read, decode and reincode these files is a first step.
Data formatting
Data is usually processed before insertion into database. Due to having heterogeneous sources, phone numbers have various format e.g., “0123456789”, “123456789”, “0033123456789”, “+33123456789” or “6789 - 0123456789”. To prevent bad format errors from occurring later in the process, the import scripts format all phone number in a standard format, say “+33123456789”.
A good test should verify that loading “0033123456789” from a CSV file ends up with “+33123456789” in db.
Data consistency
The import scripts not only load data but also establish relations upon it. For instance, imagine the script loads two csv files respectively containing people names and phone numbers:
ID
lastname
firstname
ID
phone number
424242
Obama
Michelle
424242
+33123456789
Our test should check that Michelle Obama gets the phone number “+33123456789” in the database.
Data resilience
The import script is launched every day, hence all data is refreshed every day. Let say that the app received the following two files respectively on day 0 and day 1:
ID
phone number
ID
phone number
424242
+33123456789
424242
+33123456789
424242
+33123456790
424242
+33123456791
On day 0, Michelle Obama should have two phone numbers “+33123456789” and “+33123456790”. On day 1, we expect the import script to remove “+33123456790” and to add “+33123456791” so that Michelle ends up with two phone numbers again.
How do we write the test?
The directory structure of the test folder looks like this:
test
├── import-script-test.py
├── payloads
| ├── day0 // Folder containing csv files that are loaded on day 0
| | └── names.csv
| | └── phone_numbers.csv
| ├── day1 // Folder containing csv files that are loaded on day 1
| | └── names.csv
| | └── phone_numbers.csv
| ├── day2 // Folder containing csv files that are loaded on day 2
| | └── ...
| ...
├── data
| ├── day0 // Folder containing a dump of the expected data for day 0
| | └── people.json
| ├── day1 // Folder containing a dump of the expected data for day 1
| | └── people.json
| ├── day2 // Folder containing a dump of the expected data for day 2
| | └── ...
... ...
The test import-script-test.py is written in Python and consists in:
- emptying the test database;
- loading
test/payload/day0/*.csvfiles with the import scripts; - getting a JSON extraction of the database;
- comparing “field by field” the extraction with
test/data/day0/people.json; - starting over again steps 1, 2 and 3 for day1, day2, … and so on.
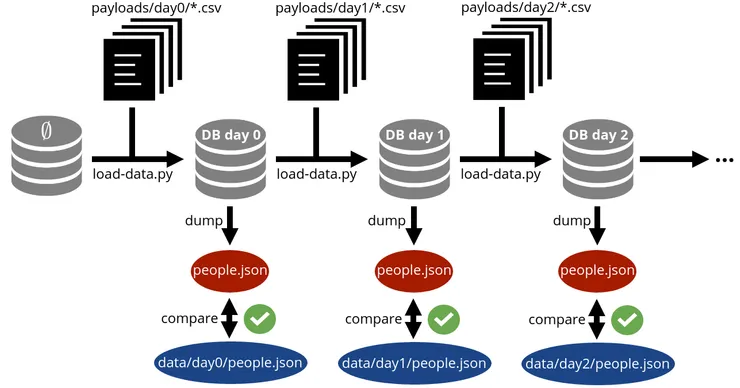
It is an end-to-end test for the import script that allows us to verify all the aforementioned points. Payload files are kept small so that the test can be easily updated. Running consecutive imports allows to check data resilience.
Epilogue
Testing the import scripts prevents many regressions due to data.
Not all projects need import scripts tests. You should evaluate the data flow of your app to decide whether it is worth it.

